STrie-vs-Binary-Search

1. Abstract
This white-paper contrasts-and-compares the superior performance of the STrie algorithm (a variant of Trie developed in 2019) against the BinarySearch algorithm (origins unknown/disputed). BinarySearch (aka BinaryChop) is still widely perceived as being the fastest data-retrieval algorithm in existence. Using simple mathematics this white-paper derives a speed formula for STrie that is up to 8 times faster than the equivalent formula of BinarySearch.
It first explains how-and-why a data-retrieval algorithm developed in the 21st century might very well be faster than those developed in the 20th century (modern computers have resources such as vast-memory and access speeds unthinkable in the 1960's). It then further examines the structure of real-world data and explores what types of algorithm might be best suited to exploit this structure. It then exposes and analyses the same hidden procedure/assumption embedded in the QuickSort, MergeSort, BinaryChop and BTree algorithms that restrict their performance to the same upper speed-limit (please note that RadialSort also avoids this hidden assumption). It then details the STrie algorithm itself and explains how it avoids this upper limit. It then derives a new speed limit formula that is up to 8 times faster than these competitor algorithms. It then explores and identifies the "downsides/watchouts" of using STrie before addressing future developments. Finally there are references to aid further research-and-development.
2. Problem Statement
The issue is principally one of speed. All deep-stack algorithms (ones used as components of higher level applications) should be under constant review to see if they can be made to run faster, or be replaced entirely by something that can. Any improvement in data-storage-and-retrieval-times would be readily adopted within IT, and significant efficiencies gained (e.g. faster file system access, faster databases, faster algorithms with embedded sorts, etc.).
Speed/efficiency is everything. Speed can be converted into money, time, carbon-offsets, or whatever. A better algorithm delivers immediate benefits to everyone; a quick-and-easy "win-win" for all.
3. Background
The STrie algorithm was not developed as either a sort algorithm or a data-retrieval-and-storage algorithm. Instead it emerged as a bi-product of another proposed development; a symbolic-processor. The STrie fast-internal-memory data-structure is a component of a symbolic-processor and follows its universal "spectral" data-model. Although AGD Research was not astute enough to create and understand STrie from first principles, with ouside direction, its potential in a wider IT context has now been quantified and demonstrated."
4. Solution
The solution is split into 5 sub-sections; advances since the 1950's, structures within data that can be leveraged, the STrie algoritm in detail and how it avoids a critical hidden assumption in its competitor algorithms, the mathematics underlying its performance, and downsides and watch-outs.
4.1 Advances since the 1960's
Any algorithm, regardless of how clever, stupid, elegant or brutal it is, uses a limited number of available resources. These are the ability to write data, to read data, to compare data and to manipulate data. In the last century when STries's competitor algorithms were developed, all of these 4 resources were at a premium, but especially the ability to read and write data quickly and in large volumes. Hence only those algorithms that were "easy" on these resources would thrive.
In recent years with new technologies none of these resources pose the same bottlenecks as before. This opens-up the possibility that an algorithm may do a "deal with the devil" where vast amounts of these cheap resources are sacrificed in the name of speed. This is precisely what STrie does; it utilizes sizeable amounts of computer memory and processing, far more than its competitors, but delivers the results more quickly.
4.2. Real-World data
Most data that any data-retrieval algorithm will encounter is encoded according to the ASCII standard. This standard is itself embedded in the last century as can be seen in its coding structure. The first 32 symbols were envisaged as control symbols for teletype machines with characters for carriage-return, line-feed, and even ringing the bell. Then the next 32 symbols contained various punctuation marks and the digits 0 to 9. The 32 symbols after that contained the upper-case letters and some more puctuation marks. The 32 symbols after that contained the lower-case letters and yet more punctuation marks. Finally the last 128 characters were left open for local symbols such as Scandinavian characters.
Typically data that needs to be retrieved will be very clustered within the 256 symbols of the ASCII standard. It will be very rare for any human-centric data to be in the first 32 characters (the control characters). Numeric data will cluster in the symbols between 33 to 64. Names, addresses and identifiers where the leading symbol is upper-case will cluster in symbols 65 to 96. Lower-case data such as words will cluster in symbols between 97 to 132. Finally certain data-sets, such as for Scandinavian character-sets, will cluster in symbols between 133 to 256.
STrie when being used as a data-retrieval engine consists of a sparse-matrix read (the details of this sparse-matrix are in the followng sub-section). The sparse-matrix is composed of columns which represent the 256 ASCII characters and rows that represent branches in a tree-structure. The number of rows tends to be somewhat larger than the number of keys/entries that are being stored. The sparse-matrix inserts and deletes are very efficient as the STrie algorithm ensures there are no surprise collisions due to hashing. However the sparse-matrix read would be inefficient if it had to read every entry. Instead during the insert phase additional meta-data marks for each row which position to start from and which to finish at for dense data, and individual points for occasional-data (3 or less points), or a mix (in a mix STrie always places individual points to the right of continuous ones as outliers are more likely towards the end of the alphabet as it was extended historically to include symbols such as w, x, y and z, and beyond these into the "exotic" characters between 128 and 255). This extra data is metametadata (data about data about data).

STrie's Sparse-Matrix showing typical "go-faster" striping metadata.
4.3. Hidden Speed-Limiting Procedure/Assumption Shared by QuickSort, MergeSort, HeapSort, BinaryChop and BTree
The hidden procedure/assumption in the above algorithms is that the only way to achieve a sort, a read or a write is to compare the whole key/entry with something else, such as another whole key/entry, then depending on the result, move or swop data. Indeed the BinarySearch algorithm makes this clear in its name. This procedure/assumption leads to an inevitable logic-chain that results in a sorting speed limited by O (n log(n)) where n is the number of keys/entries, and O (log(n)) for data-retrieval-and-storage (the big "O" notation simply means the limiting function as n tends to infinity, without worrying about minor terms etc.).
As an example the BinaryTree algorithm stores data in nodes, with each node having a potential of just 2 children (referred to as the left-child and right-child). Therfore the data-retrieval time for an individual key/entry is directly related to the number of partitioning-levels that have to be traversed to reach the key/entry. Mathematically this is saying the total-number of keys/entries is 2-to-the-power of the number-of-partitions, or n = 2 ^ p. This equation can be solved by using the inverse log function (to the base 2), giving a limiting-time for an individual key/entry of log(n).
Attempts at amending the algorithms of STrie's competitors to break this speed-limit by splitting keys/entries into more than 2 piles at each level fail (BTrees in general can have multiple children, but are no faster than BinaryTrees). Assigning a key/entry into more than 2 piles would require some ""magic"" method of doing this as comparisons are binary, not tertiary or whatever. How STrie avoids this trap is that its sub-keys/sub-entries automatically partition into piles of up to 256, their positions within each pile being the ASCII code of the first character of each sub-key/sub-entry. The "magic" is baked-in (the multi-partitioning is already coded in the key/entry)!
4.4. The STrie Algorithm
STrie avoids the above speed-limit because instead of comparing one whole key/entry with another whole key/entry, then taking some action, it decomposes each individual key/entry into sub-keys/entries and processes those to perform a data-retrieval. It does this by building a tree-structure consisting of a 2-dimensional integer sparse-matrix and a 1-dimensional string-array that represents, in pieces, all the individual whole keys/entries. The sparse-matrix represents the tree-nodes where branches diverge, and the string-array the branch values between tree-nodes. Please note that an integer sparse-matrix is a data-structure that computers can process extremely quickly and efficiently.
Taking the 2 colours Magenta and Magnolia the algorithm will create a sparse-matrix row with column 77 (ASCII character 77 is "M") set as a pointer to a string-array entry of "ag". Another sparse-matrix row then takes this further, with columns 101 and 110 (ASCII characters 101 and 110 are "e" and "n") set as pointers to the string-array entries of "nta" and "olia". This is easier understood pictorially:"
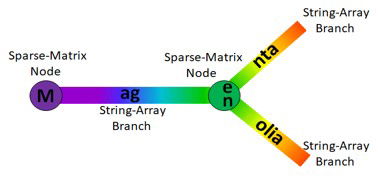
Picture of the sparse-matrix and string-arrayteaming-up to produce the STrie tree structure.
The user can explore this within the Colours tab/sheet in the bottom-right quadrant of the downloadable spreadsheet which displays the STrie metadata. The first row of the sparse-matrix has a pointer to row 43 in column 77 (ASCII character 77 is "M"). The branch string-array at row 43 contains "ag", as per the diagram. Also the sparse-matrix at row 43 has pointers to rows 15 and 44 in columns 101 and 110 (ASCII character 101 is "e" and 110 is "n"). Finally the branch string-array at row 15 contains "nta" and at row 44 contains "olia".
If the user then adds 2 additional colours, "Mauve" and "Marigold", then clicks-on the blue metadata row to re-populate the sparse-matrix and string-array, the algorithm will adjust accordingly. It will cut-short the "ag" branch to just "a" (which is common to all 4 colours) and create a new node pointing to "g" for Magenta and Magnolia, "r" for Marigold and "u" for Mauve.
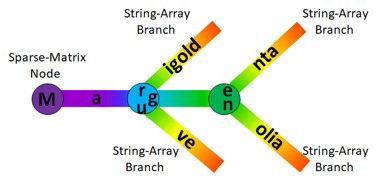
Picture of the sparse-matrix and string-array teaming-up to produce the STrie tree structure.
This is what the STrie algorithm does in its build-phase. Note that if there are duplicate keys/entries the last one encountered "wins" (e.g. if Amsterdam is in the Netherlands followed by another in the USA, a retrieve will return USA as its location). The key-understanding is the make-up of the sparse-matrix nodes. They can only ever have a maximum of 256 branches emanating from each node, one for every possible ASCII character. This number is reduced further due to the striping meta-data. This low-number enables a fast linear-scan to operate instead of having to do a binary-search to find a branch. The STrie tree-structure can be represented as a fractal shape (see below), and is shared by the "spectral" universal data-model of symbolic-processors which spawned this algorithm variant.
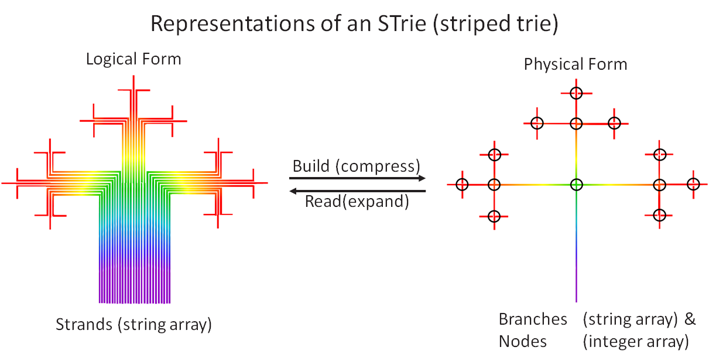
The STrie Data-Structure: Each violet-to-red line represents a key/entry, each branch represents a string-array entry, and each bend/node represents a sparse-integer-array entry. The violet-to-red colours derive from the "spectral" universal data-model of symbolic processors.
The STrie algorithm has 2 operational-modes that have various names (e.g. indexed/sequential, exact-match/near-match, etc.). The above diagram mirrors this as 2 different ways of locating a branch; either starting from the root and navigating upwards to a leaf, or starting from a leaf and navigating sideways to a successor or predecessor leaf. With STrie the first mode is faster, which mirrors real-world requirements.
4.5. The STrie Speed-Formula
To derive a speed formula for STrie a similar approach is used for those of BinarySearch etc. A series of steps is derived for each key/entry, each one consuming an amount of time and resources. In the case of BinarySearch these steps were the partitioning of the keys/entries into half, a quarter, an eighth and so on. The equivalent for STrie are the branches for each row/entry in the tree (the sub-keys/sub-entries).
The way to calculate the average number of branches in each key/row is first establish the average number of diverging branches at each node in the tree. If on average there were 10 branches per node, and there were 3 levels in a balanced tree, that would result in 1 thousand keys/entries (10 x 10 x 10 = 1000). As BinarySearch can only differentiate 2 sets per partition, it would require 10 levels (2 * 2 * 2 * 2 * 2 * 2 * 2 * 2 * 2 * 2 = 1024). In this example, assuming the time/effort required at each level is equivalent, it would mean that STrie was over 3 times faster (3 levels instead of 10 partitions).
Taking this to the limit, with a maximum number of branches per node-equivalent being 256 for STrie as compared with 2 for BinarySearch, gives an 8 fold speed superiority for STrie (2 to the power 8 is 256 representing 8 times less levels required to achieve a certain number of keys/entries to be stored/retrieved). This is where the "8 times faster than BinarySearch" banner-headline comes from. It is very much an upper limit and has 2 assumptions behind it that should be explored-and-challenged, but the formula O(n/8 log(n)) emerges (to the base 2, for n keys/entries), which is 8 times faster than its competitors.
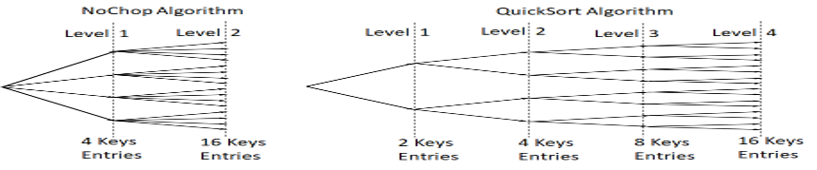
In the 2 tree-structures above we can see STrie with an average of 4 branches per node needing just 2 levels to reach 16 keys/entries, but BinarySearch needs 4 levels, twice as slow(assuming equal level times per algorithm).
The above picture, and the STrie speed formula in comparison to BinarySearch, rest on 2 assumptions. The first assumption is that the processing/time required for each algorithm is equivalent for each key/entry at each level in the algorithm. This is a reasonable assumption as at each level in the algorithms there is a chance that the key/entry has been located (return the key/entry), or continue to the next level.
The second assumption is that there are the same average number of branches-per-node at each level, which is a simplification that allows the upper-limit speed equation for STrie to be derived (using the maximum 256 branches-per-node). Instead there will be a sophisticated probability-distribution, which depending on data, would most probably see higher numbers of branches-per-node at lower levels (e.g. in the Cities tabs/sheets there are 38 initial branches representing the first letters of each city in the list). Deriving this probability-distribution is non-trivial and deserving of a white-paper on its own. So the same approach is taken with the previous assumption in that an empirical approach can best illuminate real-world distributions. The metadata includes just such information for each data-set and can be viewed in cells ""N1"" onwards in the upper-right quadrant of the tab/sheet (note that refreshing the metadata by clicking on the blue metadata-row will take an appreciable amount of time as it has to ""dump"" both the sparse-matrix and the string-array).
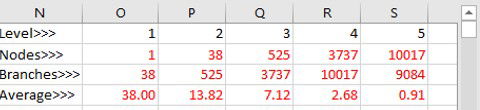
Grid showing the average number of branches per level for the Cities tabs/sheets.
4.6 Downsides and Watchouts
The STrie algorithm does have a number of considerations to factor-in. The first, as already detailed, is that STrie consumes large amount of computer resources, particularly memory. STrie is at its fastest when there are no other processes competing for memory (the user can/should kill competing processes during trialling). Although the sparse-matrix is large, by modern standards it is "manageable", but poor STrie performance may be due to memory issues (BinarySearch uses very little memory as it does not utilize any metadata).
The second consideration is stability. Stability is a technical issue which concerns itself with whether a data-retrieval algorithm can "blow-up" due to duplicates (i.e. encounter data/conditions that are so beyond its safe input "envelope" that run times become excessively long. Both BinarySearch and STrie are stable. The STrie algorithm was designed for data-storage-and-retrieval, an environment where "no-duplicates-allowed" is the ideal behaviour. Also the algorithm should be relatively immune from situations that cause excessive run-times as these could only be caused by there being keys/entries made up of tens, hundreds or thousands of levels, each level's processing adding to the run time. However as each level is represented by a minimum of 1 character this would equate to keys/entries being tens, hundreds or thousands of characters long, which for real-world-data they never are.

The number of allowable levels is limited by the maximum length of the keys/entries (the picture to the right shows a 6 level key/entry which is already rather rare for real-world data).
The third consideration are the 2 modes in which data-retrieval ideally operates; exact-matching and near-matching (this is equivalent to indexed/sequential data-retrieval). With exact-matching a key/entry is either found and returned along with its data, or it is not found and nothing is returned (e.g. a word exists in a dictionary or it does not). This is the most common use of a data-retrieval algorithm and the one that NoChop excels at (no linear-scanning of the sparse-matrix is required). The tabs/sheets prefixed with a "=" have their MatchOption set for exact-matching and show a big difference between retrieval-rates (50% or greater).
With near-matching the next-or-previous key is returned along with its data (e.g. return the word immediately above or below the key/entry). This is a less common use of a data-retrieval algorithm and one that NoChop is less differentiated (linear scanning of the sparse-matrix is required). The tabs/sheets prefixed with a ">" have their MatchOption set for near-matching and show a smaller difference between retrieval-rates (5% or greater).
"Finally, in its first iteration STrie contains approximately 330 lines of VBA code as against BinarySearch's 70 lines. This reflects the relative complexity of the 2 algorithms (BinarySearch just needs chop/discard keys/entries, but STrie is more sophisticated). With more development it is very likely that the STrie code can be further optimized, especially in a computer language with better control at the chip level (there are commands that do not exist in VBA). Currently however, the supremacy of STrie over BinarySearch appears to be 300+ percent for exact matching, and 200+ percent for near-matching, on the limited data-sets presented here. This is becoming compelling.
STrie is even more compelling if the build phase of data-retrieval is included (i.e. pre-building a sorted-list for BinarySearch or the metadata for STrie). In the empirical spreadsheet the 20th century QuickSort algorithm is used to build the sorted-list for BinarySearch. With STrie the metadata build is just a natural part of the STrie algorithm. The total-time in the spreadsheet is a good proxy for including this extra overhead-time, and results in an even greater supremacy for STrie. The watchout is that the spreadsheet STrie algorithm accompanying this white-paper should be seen as a proof-of-concept of STrie supremacy, not a finished working version.
5. Future Developments
The "call-to-arms" is for STrie to be progressed from a research stage to a development one. There are 2 clear areas where this can happen:
5.1. Exploiting STrie's Existing Demonstrated Supremacy (replacing current BinarySearch algorithm)
Retrieving data is a ubiquitous process that is necessary in all types of file-systems, databases, platforms, operating systems etc. Typically a data-retrieval-routine routine is embedded deep in the software stack so that higher-level applications can call on it and not have a dedicated routine within the application. A programme to replace the existing routines (BinarySearch) can be planned to swop this component at an appropriate upgrade point (typically a major release). For new file-systems, databases, platforms and operating systems the STrie algorithm should be chosen immediately as the "data-retrieval-routine-of-choice".
5.2. Exploiting STrie's Potential Massive-Parallelization Supremacy (industrial-scale in-memory data-retrieval, with minimal latency)
In retrieving date there are a number of processing "bottlenecks" including the application overhead, bandwidth concerns and of course the data-retrieval algorithm itself. Massive parallelization of STrie can effectively significantly reduce this last bottleneck (near zero latency).
The STrie data-structure is ideally suited to parallelization, the simplest configuration would be for 256 processing-units, each with its own memory, working together. A dedicated series of STries would be pre-built, and this "divide-and-conquer" approach would deliver results almost instantaneously.
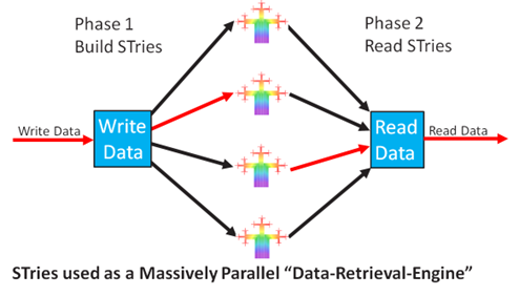
A final speed improvement is that both the input-pipe (the unsorted keys as above) and the output-pipe (the sorted keys as above) can also be massively parallelized. Data held in a single input-pipe could be chopped-up and fed into separate triaging processes simultaneously (if possible within the context). Data held in a single output-pipe could also be chopped-up and fed to separate output destinations (if possible within the context).
6. References
Wikipedia (https://en.wikipedia.org/wiki/Binary_search_algorithm)
StackOverflow (https://stackoverflow.com/questions/249392/binary-search-in-array)
KhanAcademy (https://www.khanacademy.org/computing/computer-science/algorithms/binary-search/a/binary-search)
GeeksForGeeks (https://www.geeksforgeeks.org/binary-search/)RosettaCode (https://rosettacode.org/wiki/Binary_search)
Wikipedia (https://en.wikipedia.org/wiki/Trie)
AGD-Research (https://agdresearch.com/home)
7. Author
Andrew Guthrie-Dow, AGD-Research, January 2025